




Managing Traffic Spikes - How We Built Our Own Shock Absorber

30,000,000.
Millions of customers hail rides, order food, buy groceries, listen to podcasts, or buy that dress they’ve been eyeing everyday. That’s a lot of transactions. And these tend to peak at certain times. Think Diwali Sales, IPL, New year’s and so on… And, to handle this love customers pour upon their favourite online destinations, a robust Payments Infrastructure is as imperative as getting that iPhone on discount at Big Billion Day sale. Delivering in such situations is how Juspay has earned the trust of its partners.
The Bridge that handles it all
Even though the number is significant, it fails to truly capture the scale of the problem at hand. Statistics such as averages and totals often fall short in providing a comprehensive picture. When constructing a bridge, it must be engineered to withstand the maximum load it may ever encounter. Likewise, our backend systems were meticulously designed to efficiently manage the highest levels of workload they might face.
And distribution of payments (number of payments/second) are fat tailed, meaning there is a very realistic probability for a value that is multiple standard deviations away from the mean to happen. Or to put it more simply, our peak load is very, very different from the average.
In this article, we specifically look at our database systems and how we manage load at this scale.
Hockey Stick Spike in Payments & its Effect on Databases
Spikes in traffic are a common scene in the payments landscape.Time bound events like the IPL match starts, train ticket bookings, eCommerce offers etc, where a disproportionate volume of load weighs on a point in time (say, the last minute before a match start or an end of sale, or the first minute of tatkal booking). The traffic could surge as much as 10x in a matter of minutes. By a combination of an expanding clientele and an increasing propensity of users to transact online, our peak load in just the last 3-4 years have gone from 200 payments/ sec to soon approaching 3000 payments/ sec.
Internally, one payment constitutes around 10 API calls and 100 database calls at Juspay. The peak load thus translates to a very high number of database calls. While most of these are for reads (for finding and fetching data) and could be served through replica databases, there is still a high volume of writes (inserts and updates) that necessarily go to our main database.

At Juspay, we have been using relational databases for recording real-time payment information (primarily a MySQL instance). These usually access the disk, which is a slower and costlier operation. At its peak load, the volume of database accesses - especially the writes - become a bottleneck and stretch our database systems. Much as we vertically scaled our relational database with more RAM and CPU, we soon hit upon limits: it became imperative to find a new solution.
Need for a new architecture
We considered a number of solutions to this problem when we encountered it, including sharding the existing database (breaking up data into chunks and distributing it across physical database nodes), and abstracting it out of multiple physical ones. That was given a skip because of a few domain constraints, additional overheads in managing the database and potential application changes that might be needed. Moreover, we wanted a solution we could immediately implement - we could hardly afford to brood over a problem that threatened to bring down the entire payment processing system.
And yet, despite the urgency of the fix needed, we wanted a solution that was futuristic and not just a duct tape to tide over an immediate concern. It wasn’t about winning the last war, but being able to fight the next one; with our growing scale requirements, it had to sustain exponential increases in demand.
In more physical terms, we wanted a system with very high throughputs (handling a very high number of reads/ writes per second), and could be remodeled on the existing architecture with minimal changes to business logic and application code.
Enter Redis.
Redis, as a Shock Absorber
Redis is a key-value data store. In contrast to a relational database that stores entries as relationships between columns, Redis simply maps a key to a value. While that might appear limiting for replacing a full-fledged database, there were multiple benefits we could unlock with Redis.
It is ridiculously fast compared to databases by virtue of using RAM memory instead of a disk, allowing hundreds of thousands of reads/writes per second. The lookups were also fast, happening in constant - O(1) - time.
The high throughput in Redis allowed us to use it as a buffer against traffic spikes. Our tech stack was redesigned to keep the Redis layer atop the database, and take the first hit as the traffic comes in. The new writes to the database would be captured as table objects in Redis, against the table’s primary key identifier (to be later copied to the database). The reads are checked in Redis first, and would fall back to the database only if the result isn’t found in Redis.
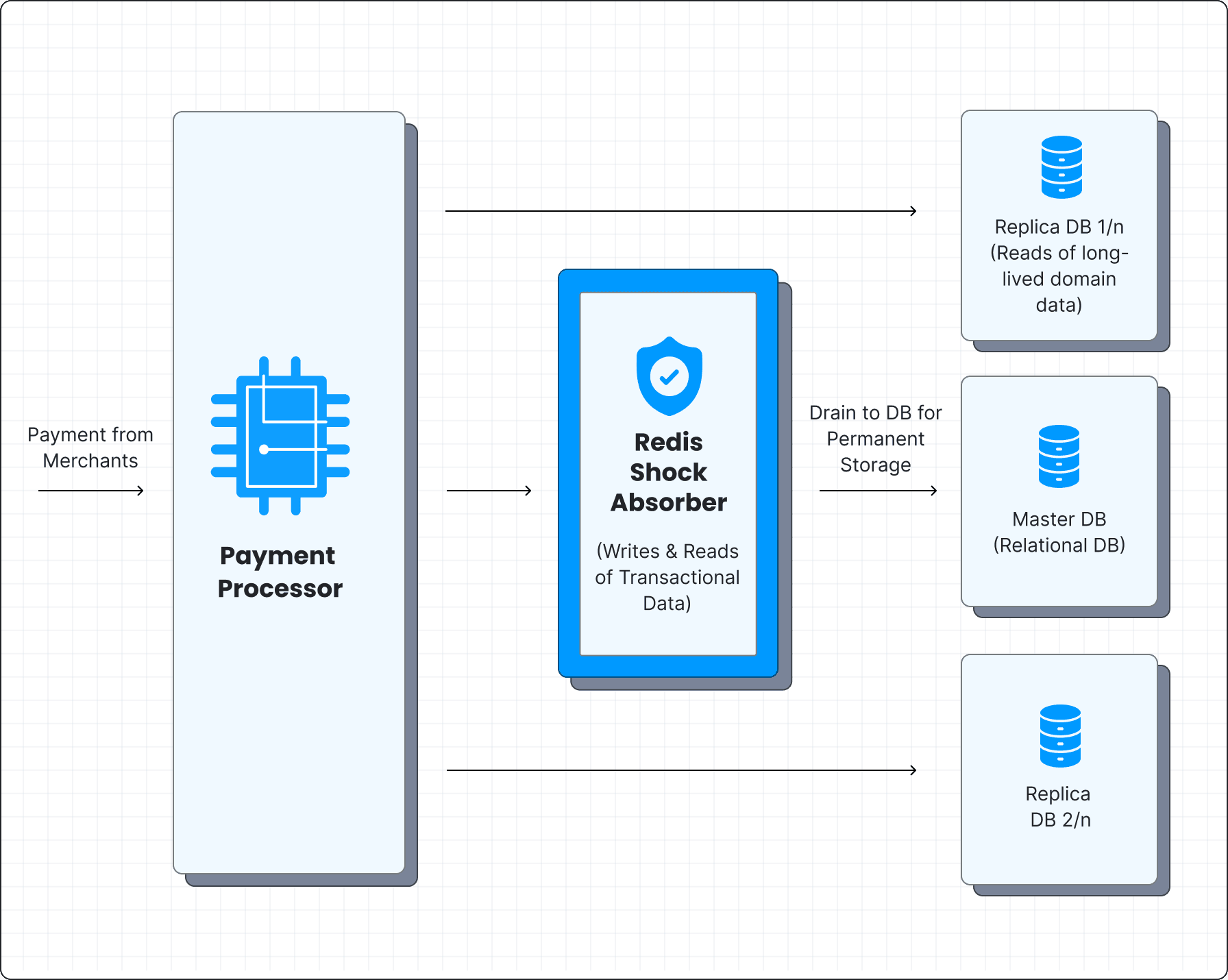
Since the data in Redis usually lives much longer than the sync lag between the database and its replicas, fallback requests to the database are for older data. These can easily be served by the replica databases without any consistency issues, absolving the primary database of any responsibility to directly serve requests.
Parallely, we also use Redis streams to house the new data in Redis with the appropriate tags. They are later decoded to the right table in the database and the actual operation to be executed. A background process called ‘drainer’ runs, which then reads these Redis streams and executes them on the database at a constant rate. A valve-like control determines the draining rate and ensures the database is never overwhelmed.
The Redis layer thus acts as a shock absorber, damping any impulses to the database even as the overall payments surge.
Implementation - Constructor Patterns
Juspay’s internal implementation in this framework involved creating an abstract layer (called ‘Mesh’) that would talk to Redis first and then the database, depending on the settings. Creates would inevitably be done in Redis; reads happen in Redis first and then go to the database as a fallback (if the result is absent in Redis). This mesh layer is presented as an abstraction, with its details hidden from the application code.
With a view to making the change as legible as possible, we also created constructor patterns within the framework to plug this feature to any table in the database. In the below pseudo code, simply calling the ‘enableKV’ function with a table will route all its DB functions through the Redis layer before the database.
#pseudo haskell code
$enableKV tablename primarykeyname [SecondaryIndices]
This vastly increased our flexibility; like DNA molecules combining to form different genes, this framework could easily whip up any pattern of tables to work with Redis. Frequently accessed tables were moved first to Redis, to later expand on need.
The framework with the constructor patterns also meant we could seamlessly use them across products. We successfully integrated this across products that faced similar problems with spiky traffic.
Adding Layers of Redundancy
In this new design, Redis became a crucial hub in our tech stack. We added layers of redundancy and alert systems to ensure that it did not become a point of failure.
To start with, we use a highly available multi node Redis cluster. These can be further scaled up/ down by adding more nodes without any downtime, for anticipated traffic spikes. Also, since the data in Redis is stored in RAM and vulnerable to loss upon restarts, we do keep backups of stream data as a hedge. And, our drainer operation too is constantly monitored to ensure nothing blocks its transcription to DB. They are further supported with automated alerts for any error or excessive lag in its operation.
We always have the option of toggling and bypassing the Redis layer for any extraneous issues (a very rare occurrence). Further additions and support are constantly made to ensure our new Redis layer is not a point of fragility.
Juspay: Sacling Up and Beyond
Although using Redis to work like a database may not suit all cases, it certainly did for us. We were also helped by the fact that database operations in our transaction flows mostly used simpler queries and could be easily served through Redis.
At Juspay, we have had a unique playbook for using Redis. Our Redis frameworks have evolved over the last few years, letting us elegantly handle almost 2500 payments/ second. With more merchants and challenges onboard, that is unlikely to be the last of the summits. Our Redis framework appears more important as we prepare to further scale up - to infinity and beyond!



